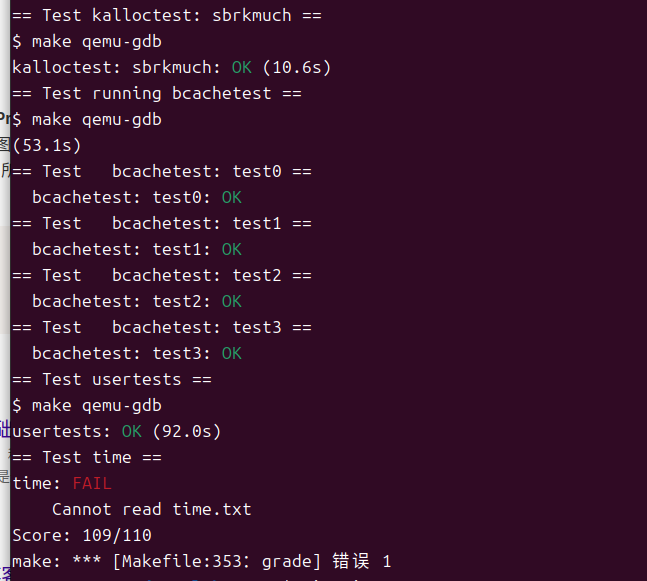
lock的实验一 链接到标题
全局变量的修改和增加 链接到标题
这里的str必须是全局变量,搞成局部变量会导致lock的name指令指向一个虚无位置
struct {
struct spinlock lock;
struct run *freelist;
} kmem[NCPU];
char str[NCPU][6];
kinit的修改 链接到标题
这里lab里说,要让每个CPU去初始化一下
hint里又说,先让一个CPU有全部的内存块
void
kinit()
{
for(int i = 0; i < NCPU;++i){
memmove(str[i],"kmem",5);
str[i][4] = i+'0';
str[i][5] = 0;
initlock(&kmem[i].lock, str[i]);
kmem[i].freelist = 0;
}
freerange(end, (void*)PHYSTOP);
struct run * t = kmem[0].freelist;
kmem[0].freelist = 0;
int i = 0;
while(t){
struct run * r = t;
t = t->next;
r->next = kmem[i].freelist;
kmem[i].freelist = r;
i++;
i %= 3;
}
}
kfree的修改 链接到标题
void
kfree(void *pa)
{
struct run *r;
if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP)
panic("kfree");
// Fill with junk to catch dangling refs.
memset(pa, 1, PGSIZE);
r = (struct run*)pa;
push_off();
int cpu_id = cpuid();
//int cpu_id = (uint64)r % NCPU;
acquire(&kmem[cpu_id].lock);
r->next = kmem[cpu_id].freelist;
kmem[cpu_id].freelist = r;
release(&kmem[cpu_id].lock);
pop_off();
}
kalloc的修改 链接到标题
// Allocate one 4096-byte page of physical memory.
// Returns a pointer that the kernel can use.
// Returns 0 if the memory cannot be allocated.
void *
kalloc(void)
{
struct run *r = 0;
push_off();
int cpu_id = cpuid();
acquire(&kmem[cpu_id].lock);
if(kmem[cpu_id].freelist){
r = kmem[cpu_id].freelist;
kmem[cpu_id].freelist = r->next;
//kmem[cpu_id].num--;
}
release(&kmem[cpu_id].lock);
pop_off();
//这里可以关了,总之开偷了肯定会有冲突
int i = (cpu_id+1)%NCPU;
// 2. 本地失败,尝试窃取
if(!r){
for(int j = 0 ; j < NCPU; ++j){//这里用NCPU保证所有内存可以分配
acquire(&kmem[i].lock);
if( kmem[i].freelist ){
r = kmem[i].freelist;
kmem[i].freelist = r->next;
release(&kmem[i].lock);
break;
}
release(&kmem[i].lock);
i++;
i%=NCPU;
}
}
if (r) {
memset((char*)r, 5, PGSIZE);
}
return (void*)r;
}
优化 链接到标题
- 每个CPU在开始时均分内存 //只有前3个,因为运行时实际上只有3个核
- kfree时看进程看自己在那个CPU上就将内存放在哪里
- kalloc在有时,只从自己身上拿,没有时窃取
坑 链接到标题
- 一定要在linux上跑,不能在wsl上,在wsl上永远过不了test3。
- KIMI跟我说要优化,一次偷别人的一半的内存搞得我走了好久弯路。
lock的实验二 链接到标题
定义修改 链接到标题
struct {
struct spinlock lock;//保留这里是为了bpin和bunpin不用修改,目前不知道这两徒弟是干啥的
struct buf buf[NBUF];
struct spinlock buf_spin_lock[NBUF];//每个buf状态的访问锁
// struct buf head;
} bcache;
所有锁的初始化 链接到标题
void binit(void) {
initlock(&bcache.lock, "bcache");
for (int i = 0; i < NBUF; ++i) {
initsleeplock(&bcache.buf[i].lock, "buffer");
initlock(&bcache.buf_spin_lock[i], "bcache");
}
}
bget改成hash查找 链接到标题
他hint里说要搞个hash表,让后用13个的大小,搞什么桶什么什么乱七八糟的,我懒得看了,直接搞了个30大小的hash,按访问dev和blockno这两变量hash一下,冲突了就用顺序查找。
static struct buf *bget(uint dev, uint blockno) {
struct buf *b;
// Is the block already cached?
// Not cached.
// Recycle the least recently used (LRU) unused buffer.
uint hash = (dev + blockno) % NBUF;
for (int i = 0; i < NBUF; ++i) {
b = &bcache.buf[hash];
acquire(&bcache.buf_spin_lock[hash]);
if (b->dev == dev && b->blockno == blockno) {
b->refcnt++;
release(&bcache.buf_spin_lock[hash]);
acquiresleep(&b->lock);
return b;
}
release(&bcache.buf_spin_lock[hash]);
hash = (hash + 1) % NBUF;
}
hash = (dev + blockno) % NBUF;
for (int i = 0; i < NBUF; ++i) {
b = &bcache.buf[hash];
acquire(&bcache.buf_spin_lock[hash]);
if (b->refcnt == 0) {
b->dev = dev;
b->blockno = blockno;
b->valid = 0;
b->refcnt = 1;
release(&bcache.buf_spin_lock[hash]);
acquiresleep(&b->lock);
return b;
}
release(&bcache.buf_spin_lock[hash]);
hash = (hash + 1) % NBUF;
}
panic("bget: no buffers");
}
block buffer的release 链接到标题
这里反而简单了,就直接–就行,因为没有链表了
void brelse(struct buf *b) {
if (!holdingsleep(&b->lock))
panic("brelse");
releasesleep(&b->lock);
int position = b - bcache.buf;
acquire(&bcache.buf_spin_lock[position]);
b->refcnt--;
release(&bcache.buf_spin_lock[position]);
}
坑 链接到标题
- 头文件不要瞎jb改位置,改了会编译不通过,我该是因为lazy vim的语法检测自动改了,我还不知道怎么调
结果 链接到标题